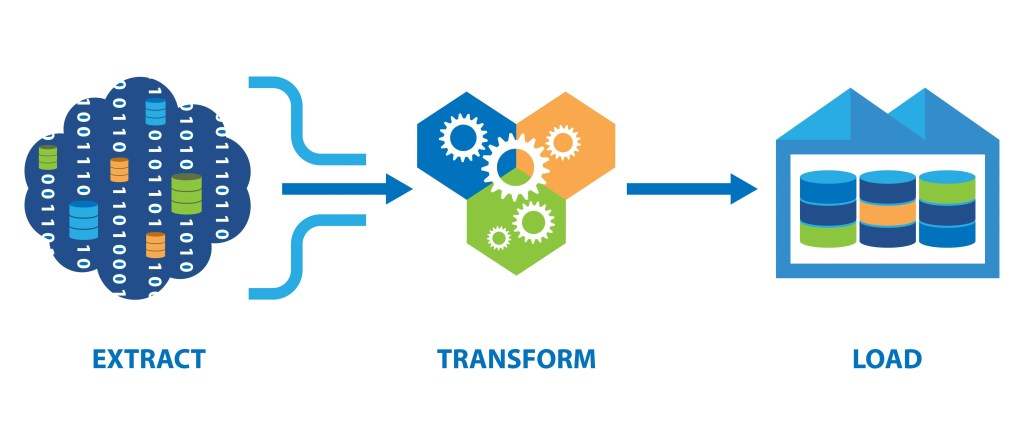
ETL Overview
ETL stands for Extract, Transform, Load. It’s a data integration process used to collect data from various sources, transform it according to business rules, and load it into a target data store, often a data warehouse. ETL is a critical component in data warehousing and business intelligence.
Components of ETL
- Extract:
- Objective: Collect data from different source systems.
- Sources: These can include databases (SQL, NoSQL), APIs, flat files (CSV, JSON), web services, or other data repositories.
- Challenges: Handling different data formats, ensuring data consistency, and dealing with large volumes of data. Example:
- Extracting customer data from a CRM system.
- Extracting logs from an application server.
- Transform:
- Objective: Convert the extracted data into a suitable format or structure for analysis. This includes cleaning, filtering, aggregating, and enriching the data.
- Steps:
- Data Cleansing: Removing duplicates, correcting errors, handling missing values.
- Data Formatting: Converting data types, normalizing data.
- Data Aggregation: Summarizing data, e.g., calculating totals or averages.
- Data Enrichment: Enhancing data with additional information, e.g., adding geographic data to customer records.
- Tools and Techniques: SQL queries, Python scripts, data transformation tools like Apache Spark, Apache Beam, or specialized ETL tools like Talend or Informatica. Example:
- Converting dates from various formats into a standard format.
- Calculating monthly sales totals from daily sales records.
- Load:
- Objective: Move the transformed data into a target database, data warehouse, or data lake.
- Types of Loading:
- Full Load: Loading the entire dataset at once.
- Incremental Load: Loading only new or updated records since the last load.
- Challenges: Ensuring data consistency, handling large data volumes, managing load performance, and dealing with failures or rollbacks. Example:
- Loading the processed customer data into a data warehouse for reporting.
- Loading transformed log data into a big data store like Hadoop or Google BigQuery.
ETL Process Flow
- Data Extraction: The ETL process begins with extracting data from source systems.
- Data Transformation: After extraction, data is cleaned, transformed, and formatted according to business rules.
- Data Loading: The transformed data is loaded into the target system, often a data warehouse.
ETL Tools
There are various ETL tools available, each offering different features:
- Open Source:
- Apache NiFi: For automating data flows.
- Talend Open Studio: Provides a graphical interface to design ETL processes.
- Apache Airflow: A workflow automation tool, often used for scheduling ETL jobs.
- Commercial:
- Informatica PowerCenter: An enterprise-level ETL tool known for its robustness.
- Microsoft SSIS (SQL Server Integration Services): Integrated with Microsoft SQL Server for ETL tasks.
- IBM DataStage: Another enterprise-grade ETL tool.
- Google Cloud Dataflow: A fully managed service that can run Apache Beam pipelines.
- Cloud-based ETL:
- AWS Glue: A managed ETL service on AWS.
- Google Cloud Dataflow: Used for stream and batch processing, particularly with Apache Beam.
- Azure Data Factory: A cloud-based data integration service.
ETL vs. ELT
- ETL: The traditional approach where data is transformed before loading into the target.
- ELT: Extract, Load, Transform; data is loaded into the target first (e.g., a data lake) and then transformed as needed. This is common in big data scenarios where the storage system (like a data lake) is highly scalable.
ETL Best Practices
- Understand Data Sources: Thoroughly understand the structure and format of your data sources.
- Data Quality Checks: Implement checks to ensure data integrity during extraction and transformation.
- Performance Optimization: Optimize extraction queries, use indexing, and parallel processing.
- Error Handling: Implement robust error handling and logging.
- Incremental Loads: Use incremental loads to improve performance and reduce load times.
- Scalability: Design the ETL process to scale with data volume.
Use Cases of ETL
- Data Warehousing: Loading data from multiple sources into a central repository for analytics.
- Data Migration: Moving data from legacy systems to modern databases.
- Data Integration: Combining data from various sources for a unified view.
By mastering ETL processes and tools, you can ensure that data is accurate, consistent, and ready for analysis, which is essential for informed decision-making in any organization.
